Trajectory: Teaching Claude Code to Learn Without Touching Model Weights
When you are a developer, everything is a coding problem


AI is moving fast, and keeping up is tough. So I built a tool to read through 50 or so blogs, papers, and other resources to help me keep up with the latest developments. It worked well, but if well was enough, I wouldn’t be writing this post.
Naturally, I wanted to LLMs to summarize it. But I quickly discovered that the models were not able to summarize the material in a way that was useful. They were either too verbose or too brief. They were either too technical or too simple. They were either too general or too specific. Tweaking the prompts and parameters helped but that seemed like a lot of work. Instead, I decided to use reinforcement learning to train the models to summarize the material in a way that was useful. Which of course was way more work than summarizing the material, or you know even reading like a human would.
Either way, I built a tool that applies reinforcement learning to prompts, allowing the prompts to learn from the outcomes of the summaries. It was a fun exercise in reinforcement learning and hopefully someone else will find a way more practical use for it.And reinforcement learning is doing a lot of heavy lifting in that sentence, probably closer to averaging. The RSS reader is a simple example of reinforcement learning, but it’s not the only one. If I had the time I’d like to test it against code development, using PR comments as the feedback signal. Future me will have to do that.
I built it on Claude Code. Here’s a little background. Every Claude Code session you run today starts from scratch. You might solve the same type of problem brilliantly on Monday—refactoring a legacy module, writing integration tests, architecting a new service—and then on Wednesday, the agent has no memory of what worked. No accumulated wisdom. No pattern recognition across sessions. The only way to get consistency is dump everything into a prompt file (or CLAUDE.md file).
So I worked on a tool call Trajectory. It’s an open-source Go project that runs as an MCP server alongside Claude Code. After every session, you score the outcome from 0 to 1. Over time, the system learns which configurations, prompts, and strategies work best for which types of tasks. Your CLAUDE.md file evolves based on real outcomes.
The insight behind Trajectory is simple: the prompt itself is the policy. Traditional RL updates model weights to learn better behaviors. But we don’t have access to Claude’s weights, and even if we did, we probably wouldn’t want to fine-tune on our idiosyncratic coding sessions. Instead, Trajectory treats your CLAUDE.md file—and the strategy profiles defined within it—as the thing that learns.
The Problem With Stateless Agents
Here’s what happens in every Claude Code session:
Claude reads your CLAUDE.md file
Claude receives your task
Claude executes, making tool calls along the way
Session ends
All learning is discarded
The conversation history vanishes. The patterns that worked—and the ones that failed—disappear into the void. Next session, you’re starting over.
This isn’t a new observation. Companies like Letta are building “AI with advanced memory that can learn and self-improve over time.” Mem0 calls itself a “universal memory layer for AI agents.” The industry recognizes that statelessness is a problem.
But most solutions focus on memory: retrieving past context, storing conversation snippets, building knowledge graphs. What I wanted was something different. Not just remembering—but learning. Improving the agent’s behavior systematically across sessions.
The Insight: CLAUDE.md as Policy
Your CLAUDE.md file already specifies how Claude should behave. It contains instructions, preferences, constraints, few-shot examples. It’s effectively a policy specification—telling the agent what actions to take in different situations.
What if that policy could evolve based on outcomes?
Here’s the mental model: imagine you have several “strategy profiles”—named bundles of instructions in your CLAUDE.md. One profile called “thorough-planning” front-loads design work before coding. Another called “fast-iteration” emphasizes quick, small changes with frequent commits. A third called “test-first” prioritizes writing tests before implementation.
Different tasks call for different strategies. Architecture work probably benefits from thorough-planning. Bug fixes might work better with fast-iteration. New features might need test-first.
But which strategy works best for which task type? You could guess. Or you could let the data tell you.
How Trajectory Works
The architecture has four components:
1. The MCP Server
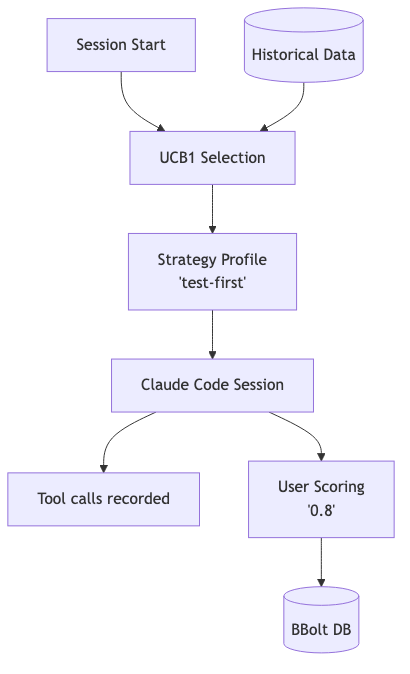
Trajectory runs as an MCP (Model Context Protocol) server alongside Claude Code. When you start a session, it registers as an available tool provider. This is non-invasive—it doesn’t modify Claude Code itself.
2. The Hooks
Claude Code’s PostToolUse hooks fire after every tool invocation. Trajectory intercepts these and records each tool call into an embedded BBolt database. Every session becomes a “trajectory”—a sequence of actions with timing and metadata.
The hooks are the key architectural insight. They provide an observation point without modifying the agent’s behavior. You’re instrumenting the session, not constraining it.
3. The Scoring CLI
After a session ends, a simple command-line prompt asks: “How’d that session go? (0-1)”. You provide a score based on whether the session accomplished what you wanted.
Yes, this is simple. Intentionally so. I experimented with automated metrics—lines of code changed, test pass rate, time to completion—but they’re all gameable or misaligned with actual outcomes. A session that produces clean code but misses the point should score low. A session that’s messy but solves the real problem should score high. Human judgment, for now, is the most robust signal.
4. The Strategy Selection
When you start a new session, Trajectory uses UCB1—a classic multi-armed bandit algorithm—to select which strategy profile to inject. UCB1 balances exploration (trying less-tested strategies) with exploitation (using strategies that have worked well historically).
Over time, the system learns: for architecture tasks, thorough-planning wins 70% of the time. For bug fixes, fast-iteration has the highest average score. For greenfield features, test-first edges out the alternatives.
The Context Optimizer
Strategy selection is half the system. The other half is more interesting.
Trajectory analyzes patterns across high-scoring and low-scoring trajectories. What tool call sequences correlate with success? What failure modes repeat? Are there instructions in CLAUDE.md that are routinely ignored or misinterpreted?
Based on this analysis, the Context Optimizer proposes edits to marked sections of your CLAUDE.md. You mark regions with special comments—<!-- trajectory:optimize -->—and the system suggests rewrites based on what’s actually working.
This is where “prompt engineering” becomes “context engineering.” Instead of manually iterating on your CLAUDE.md based on intuition, you’re running a feedback loop that surfaces what the data says.
Here’s an example. My original CLAUDE.md had an instruction:
When refactoring, prioritize readability over performance.
After 20 scored refactoring sessions, the Context Optimizer noticed that high-scoring sessions had something in common: they included explicit performance benchmarks before and after changes. The system proposed:
When refactoring, prioritize readability over performance.
Always run benchmarks before and after to verify no regressions.
A small change. But it emerged from data, not guesswork.
Why UCB1 Is Enough
You might wonder: why use a simple bandit algorithm when you could apply deep RL, Monte Carlo Tree Search, or some sophisticated policy gradient method?
The answer is that the action space is small. If you have 10-50 strategy profiles, UCB1 is plenty. You’re not learning a complex policy over a high-dimensional action space; you’re learning which of a few dozen configurations performs best for which task types.
More sophisticated approaches would require more data than most individual developers will ever generate. I run maybe 20-30 Claude Code sessions per week. Over a year, that’s 1,500 scored trajectories. That’s enough for a bandit to converge reliably. It’s not enough to train a neural policy from scratch.
Simpler is better here. UCB1 has convergence guarantees. It’s interpretable. You can inspect the arm statistics and understand exactly why it’s making the choices it makes.
What This Isn’t
Trajectory is not a fine-tuning solution. The model weights never change. This is important for a few reasons:
No training infrastructure required. You don’t need GPUs or training pipelines. The system runs on your laptop.
No data leaves your machine. Your trajectories stay local. You’re not sending session data to anyone’s servers.
No model access required. You don’t need API access to weight updates. You’re optimizing what you control: the context.
It’s also not a memory system in the traditional sense. Trajectory doesn’t retrieve past conversation snippets or build a knowledge graph of facts. It learns at a higher level of abstraction: which strategies produce good outcomes.
What Smarter People Have Already Done
I’m not the first person to think about learning for LLM agents. Here’s how Trajectory compares:
Microsoft’s Agent Lightning applies RL to train LLM agents, but requires actual training infrastructure. For organizations with that capability, it’s powerful. For individual practitioners, it’s out of reach.
DSPy from Stanford offers algorithmic prompt optimization, but it’s framework-specific. You need to rewrite your workflows in DSPy’s abstractions. Trajectory works with any existing CLAUDE.md—no framework lock-in.
GEPA (ICLR 2026) showed that “reflective prompt evolution can outperform reinforcement learning.” This validates the core idea that prompt-level optimization is competitive with weight updates. But GEPA is research code; Trajectory is meant to be used.
The gap I’m trying to fill: practical, open-source, Claude Code-native learning that runs locally without infrastructure or framework requirements.
What I’ve Learned Building This
Building Trajectory has changed how I think about AI tooling.
First: the context window is underrated as a learning substrate. Everyone’s obsessed with weights. But the context window is massive, malleable, and under your control. You can fit a lot of policy specification into 200k tokens.
Second: simple scoring beats complex metrics. I spent weeks trying to automate session scoring. None of it worked as well as just asking “did this accomplish what you wanted?” The human-in-the-loop pattern isn’t just pragmatic; it’s more robust.
Third: bandit algorithms are appropriate more often than people think. The ML community defaults to neural networks, but for small action spaces with limited data, classical algorithms dominate.
Fourth: Go + BBolt is a nice stack for local-first tools. Single binary, no dependencies, embedded database. It just works. Python would have been faster to prototype, but Go ships better.
What Surprised Me
The contrarian result. I built Trajectory expecting it to confirm my assumptions about what makes a good session. It didn’t. For the RSS briefing task, I was certain that “curated” (careful selection, editorial judgment) would beat “comprehensive” (cover everything, let me filter). The system disagreed. After 15 sessions, comprehensive had a higher average score.
This is the whole point. If Trajectory only confirmed what I already believed, I wouldn’t need it. The value is in surfacing preferences I didn’t know I had. Turns out my definition of “good briefing” is less about comprehensive coverage and more about intellectual challenge—being pushed toward articles I wouldn’t have chosen myself. I probably should have known that about myself, but it took a bandit algorithm to make it explicit.
Bug-catching as a side effect. Recording every tool invocation creates an audit trail I didn’t anticipate using. During one session, Trajectory caught a bug where the agent was overwriting a file instead of appending to it. That wasn’t the goal of the system, but when you can see the full execution trace—read this file, wrote that file, ran this command—bugs that would normally hide in the flow become obvious.
Human feedback is the real signal. The automated parts work fine. The recording is seamless. The bandit selection is fast. The trajectory search retrieves relevant examples. But the meaningful improvements come from the scored feedback and the notes I add alongside scores. “Too many short articles.” “Good topic selection but shallow on AI regulation.” Those notes drive the context optimization. The system is only as good as the feedback you give it. This is true of all RL—the reward signal is everything.
Cold start is real but short. The first 4-5 sessions feel random because they are. The bandit is exploring, trying each arm to establish baseline statistics. But even during cold start, the trajectory store is accumulating examples that improve future sessions. By session 10 you have meaningful differentiation between strategies. By session 15 the system has genuine opinions about what works for what. For a daily task, that’s two weeks. For something you run multiple times a day, it’s a couple of days. Patience during cold start pays off.
What’s Next
I’m giving a talk on Trajectory at AI Tinkerers Calgary in March. That’s the forcing function for open-sourcing it.
After the talk:
Public GitHub repo with installation instructions
Documentation for defining strategy profiles
Examples of Context Optimizer patterns
A Discord or discussion forum for people building similar tools
Longer term, I’m interested in:
Task type classification: Automatically detecting whether a session is “architecture” vs “bug fix” vs “greenfield” based on the initial prompt
Multi-user learning: Can patterns from my sessions improve your CLAUDE.md, while respecting privacy?
Proposing Trajectory for Claude Code integration: This would work better as a first-class feature than a side-car
I’m still figuring out a lot of this. The scoring rubric is crude. The task type boundaries are fuzzy. The Context Optimizer’s suggestions aren’t always useful.
But I’ve been running Trajectory for about 30 sessions now, and something interesting is happening: my Claude Code sessions are getting measurably better. Not because the model improved—but because my context did.
More unexpectedly, I’m learning about my own preferences. Turns out I work differently than I thought I did. The bandit doesn’t care about my theories of good practice—it cares about what actually produces outcomes I score highly. Sometimes those align. Sometimes they don’t. The disagreements are where the real learning happens.
If you want early access or want to contribute, the repo will be public after AI Tinkerers Calgary in Feb: github.com/johncarpenter/trajectory-memory. Find me on LinkedIn if you’re building something similar.